



Welcome Back!
Today one of my favorite LessWrong contributors, Zvi, writes about AGI and GPT Agents. Luckily for us, he also writes on Substack.
Zvi is a highly original thinker and analyst around A.I., including A.I. risk. LessWrong is a community blog and forum focused on discussion of cognitive biases, philosophy, psychology, economics, rationality, and artificial intelligence, among other topics. Zvi has over 550 posts there, many long and detailed. You can subscribe to his posts on the top right here.
🚨 LessWrong for me is an important sounding board on contemporary A.I. risk issues. If that topic is of interest, read this post to the end.
Click on the title to read on the web or go here if Gmail says you are at the limit. Reading on the app is the best experience.

😨🔎 On to today’s important topic! ☠️💬
GPT Agents and AGI
By Zvi, May, 2023.
Could future large language models (LLMs) become the key component of a future artificial general intelligence (AGI) that is smarter and more generally capable than humans?
Could such an AGI then pose an existential threat to humanity?
For current LLMs like GPT-4 (and ChatGPT) the answer is a definitive no.
For a next-generation model, a GPT-5 worthy of the name, what about then?
Probably not. Yet maybe.
We cannot take much comfort in an LLM’s inability to plan, have goals or be an agent, because people are already building scaffolding to transform LLMs into agents that plan in order to achieve particular goals.
We call such programs AutoGPTs.
We also cannot presume that the goals chosen will be wise. Already we have ‘ChaosGPT’ whose ultimate goal is explicitly to destroy humanity. The most common goal people give such systems? “Make paperclips.”
What Is AutoGPT?
AutoGPT takes an LLM and turns it into an agent.
The initial program was created by game designer Toran Bruce Richards.
The concept works like this:
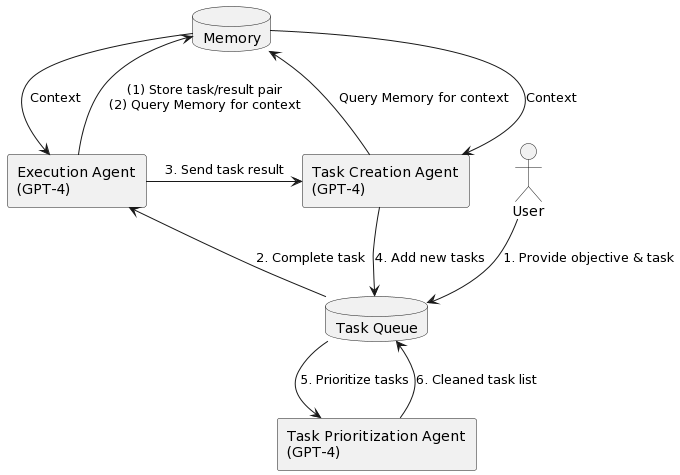
This system uses GPT-4 in three distinct places.
GPT-4 attempts to execute individual tasks and subtasks directly.
GPT-4 generates new subtasks for tasks it cannot execute directly.
GPT-4 prioritizes among its tasks and subtasks.
The AutoGPT program tracks what tasks are in the queue, and has memory that provides context for task execution, creation and (presumably also) prioritization. When tasks or subtasks fail, AutoGPT evaluates the situation and attempts to course correct.
Plug-ins including internet browsing are used to execute tasks. Often AutoGPT is given disk read/write access.
AutoGPT quickly became #1 on GitHub. Lots of people are super excited. Many are building tools for it. There is a bitcoin wallet interaction available if you never liked your bitcoins. AI agents offer very obvious promise, both in terms of mundane utility via being able to create and execute multi-step plans to do your market research and anything else you might want, and in terms of potentially being a path to AGI and getting us all killed.
Read more of Zvi
Did We See AutoGPTs Coming?
As with all such new developments, we have people saying it was inevitable and they knew it would happen all along, and others that are surprised. We have people excited by future possibilities, others not impressed because the current versions haven’t done much. Some see the potential, others the potential for big trouble, others both.
Also as per standard procedure, we should expect rapid improvements over time, both in terms of usability and underlying capabilities. There are any number of obvious low-hanging-fruit improvements available.
An example is that many people have noted ‘you have to keep an eye on it to ensure it is not caught in a loop.’ That’s easy enough to fix. Similarly, it seems easy to get rapid improvement on many tasks using special logic. There is great potential in using specialized fine tuned models for appropriate subtasks, or for different steps of the process.
A common complaint is lack of focus and tendency to end up distracted. Again, the obvious things have not yet been tried to mitigate this. We don’t know how effective they will be. No doubt they will at least help somewhat.
It is still very early. For now, AutoGPTs are not ready for prime time. We got a quick flurry of ‘look at what AutoGPT can do.’ What we did not get was any ability to keep them on track, or to get them to execute complex tasks in creative ways.
Evolved forms of AutoGPT hold great promise. For now, they do not offer much mundane utility.
What Will Future Versions Do?
Future versions, even based on GPT-4, will have better memories, better focus, better self-reflection, better plug-ins, better prioritization algorithms, better ways for humans to steer while things are progressing, better monitoring of sub-tasks, better UIs (e.g. there is already a browser-based AgentGPT), better configurability, better prompt engineering and so on.
This will happen even with zero fundamental innovations or other AI advances, and without any insights into AutoGPT design.
This process will rapidly shed a light on what things are actually hard for the underlying LLM to handle, and which things only require the right scaffolding.It seems reasonable to expect a number of large step-jumps in capability for such systems as various parts improve.
AutoGPT needs to reduce its tasks into subtasks that GPT-4 can complete. As we get the ability to do larger subtasks reliably, or to figure out how to define subtasks such that they can be completed and accomplish larger tasks such that the new larger task effectively counts as a completable subtask, new possibilities open up. If you know what you want a particular such AutoGPT to do, you can create special checks and logic to expand upon this.
Woe to those who don’t extrapolate here.
Editor’s Note: I’m starting to engage more in dialogues in Chat on the Substack app around important themes of A.I. Want to join me?

Crossing the Threshold
What might happen in the future if we had superior agent-generating architecture, and hooked it up to something worthy of the name GPT-5, or 6 or 7?
Perhaps remarkably little, if such systems continue to turn out to lack key elements. If they don’t, perhaps the end of everything.
A language model, in order to best predict text, needs to understand the systems of the world. A sufficiently advanced LLM will, upon request, be able to plan well, and to solve many subtasks.
At some point, your agent becomes sufficiently capable and robust to accomplish complex multi-step goals. Various humans will then point it at various goals. Some of these goals will be maximalist goals, like ‘make the most money’ or ‘world peace.’ Some will be actively destructive.
Such an agent, if sufficiently capable already, and which may or may not already be a full AGI, will then generate a subtask to expand its capabilities - to seek some combination of intelligence, skills, power, compute, money, information and so on. If it is capable of doing that, it will then use that new leverage to seek out yet more, and repeat in a cycle of recursive self-improvement and self-empowerment. While doing so, it will also generate subtasks like ‘prevent anyone from turning the system off or modifying the goal’ because those events would stop it from achieving its goal.
That’s instrumental convergence. What helps you do almost anything? Power.
Where does this end, once it starts? It might not stop at all, until this progressively smarter and more powerful monster we created takes over everything.
Such systems could easily go very quickly from ‘not good enough to snowball’ to existential threats once they get started. By then, it would be too late.
Read More with Zvi [link]
The Agent Overhang
If agents are dangerous, should we avoid and discourage agents and agent scaffolding? Or should we encourage development of better agent scaffolding, to avoid having an ‘agent overhang’ of easily accessible new capabilities that will inevitably be tapped at a worse time?
Future agents that take AutoGPT form, which potentially are also future AGIs, consist of an LLM and scaffolding around the LLM, that in combination are sufficiently capable.
If we want to prevent future agents from reaching a critical mass of capabilities until we can ensure control over their behavior, and avoid them falling into the hands of those who would give out destructive goals, we can either target the scaffolding or we can target the LLM itself.
The problem with targeting the scaffolding is that the scaffolding is a tiny Python program. Future versions will be longer and more complex with more components, but attempting to prevent their development over time seems hopeless. Whatever the LLMs we create can do, humans will find a way to do it, no matter how foolish that might be.
If we are in danger, we will find little hope in either humans not creating strong scaffolding, or in convincing all humans to always choose their prompts wisely.
AutoGPTs are also typically open source. Open source software, once it gets out into the world, cannot be controlled or contained, and it cannot be protected from modification. Its safety features are only as good as people’s willingness to not remove them.
If we allow this ‘Linux moment’ to spread to future more powerful base models, in the style of Meta’s Llama, then no one will have the power to stop what happens next.
We can mainly find hope in controlling the creation of future more powerful models, or in limiting access to those models, so that future agents lack the potential capabilities necessary to be sufficiently dangerous.
To achieve this, it is helpful to know what would constitute a dangerous model. If we know approximately where the threshold is likely to be, we have better chances to avoid crossing that threshold.
It is also helpful now to have models that are dangerous now, in ways that are not existential and will not be so lethal or expensive. This alerts more people to the dangers future models will pose, and allows a better case that we need to beware the creation of such models. It also allows us to develop defenses and mitigation strategies and detection methods, either by modifying the ‘standard’ code we use to make agents (while remembering anyone can remove or disable such safety codes, and some will try) or by learning how to change the internet, tech landscape or world to provide incremental protections.
This is a strong argument in favor of encouraging development of more agents and agent scaffolding.
There are also strong arguments pushing against this.
The argument for solving the overhang implies we will inevitably find the correct scaffolding architectures. This is not obvious. Perhaps with less practical experience and tinkering, we will not do so, in which case the overhang might persist indefinitely, and we don’t want to close it. Or perhaps we want to wait until regulation is more set, so it isn’t structured around agents.
Getting people into the habit of using and being excited by agents, and hooking agents up to things, could make the world more rather than less vulnerable for future agents, if we continue to do so as foolishly as we have so far. Precautions in response to mishaps might instill false confidence.
The more we develop better agents, the more this pushes general AI capabilities towards dangerous levels faster, as AI will get even more attention and funding, and the agents themselves could help with development even before they are existentially dangerous on their own.
On balance, I continue to favor shrinking the agent overhang, but this could easily be wrong.
Editor’s Note: Polls are my addition.

Is the 2023 Speed of A.I. Augmenting Risk?
The Core Problem
Geoffrey Hinton, the Godfather of AI, cuts to the heart of the problem.
He warns, how often does a less smart thing stay under the control of a much smarter thing?
Such a situation is not impossible to sustain, yet it is extremely unlikely and difficult.
Humans control the world and the future because humans are the smartest entities and the most powerful optimizers on the planet. Increasingly the world’s atoms are arranged how we want them arranged, limited only by our lack of further intelligence, technology and optimization power.
What happens if we hand those titles over to one or more AGIs, which would then likely rapidly be quite a lot smarter and quite a lot better at optimizing how atoms are arranged? That are assigned various goals by various people that cause them to seek power? That are better at almost all skills, including manipulating humans, than any human has ever been?
The future would then rapidly belong to those AGIs. If we have not robustly solved the alignment problem by then, and figured out how to make those AGIs collectively give us a future we value, we will likely not have a place in that future, or much value what comes after us, for long.
GPT agents show us that ‘they aren’t agents’ is at most a temporary stumbling block towards this outcome. Finding a solution is humanity’s greatest challenge.

Did you enjoy this post? Why not Restack it on Notes.
The Path to AGI
Thanks for reading!
Read more on Zvi’s Substack
There are so many great writers now in and around A.I. and futurism on Substack. I’m trying my best to bring attention to them on Notes.
If you find my coverage, curation and community valuable, you can support the channel. This is my full-time job.
Collabs with the Publication
This publication is actively accepting pitches for guest posts and inviting A.I. brands and A.I. tool builders to Sponsor the Newsletter with a headline Ad. If interested go to my Paved. Want more reading? Go to the publication’s Subreddit of links and web articles.
 | A guest post by
|
I keep reading about the "risks" of AI, most of which seem to boil down to things like its ability to create deepfakes, hack accounts, and possibly become our Overlord. The REAL danger is much more present: The Culture Wars, Future Shock, and the Rise of Fascism in the Age of AI
In 1970, Alvin Toffler published "Future Shock," a book that predicted a future in which the pace of change would accelerate so rapidly that it would leave countless individuals feeling alienated and overwhelmed. As we find ourselves immersed in the era of artificial intelligence (AI) and rapid technological advancements, it seems Toffler's predictions are becoming reality. The culture wars that have emerged in recent years can be seen as a manifestation of the societal dissonance caused by this accelerating change. This essay will examine the connection between Toffler's "Future Shock," the culture wars, and the resurgence of fascist ideologies in response to the overwhelming pace of change.
The Culture Wars and Future Shock
The culture wars are characterized by deep divisions and conflicts within societies, often stemming from differing perspectives on issues such as immigration, gender roles, and economic inequality. As the pace of technological advancements has increased, so too has the rate at which society must adapt to these changes. This rapid transformation can be disorienting for many, leading to feelings of alienation and disconnection—feelings that Toffler described in "Future Shock."
As AI technology continues to advance, it raises concerns not only about the potential for the emergence of superintelligent entities but also about the societal changes that such advancements will inevitably bring. The speed at which AI is developing can be intimidating, and the inability of individuals and institutions to adjust to these rapid changes can lead to the escalation of culture wars.
The Rise of Fascism in the Age of AI
In times of uncertainty and rapid change, it is not uncommon for people to turn to ideologies that offer a sense of stability and familiarity. Fascism, with its emphasis on nationalism, traditional values, and authoritarian leadership, can provide a comforting sense of order in a world that feels increasingly chaotic.
The rise of far-right political movements and the resurgence of fascist ideologies can be seen, at least in part, as a reaction to the disorientation and alienation brought on by the rapid pace of not only social change but also technological advancements. The desire to return to a simpler time, where traditional values held sway and life seemed more predictable, can be an attractive prospect for those who feel overwhelmed by the uncertainty that accompanies rapid societal change.
However, the allure of fascist ideologies represents a clear and present danger. The authoritarian nature of these beliefs, coupled with their propensity to scapegoat marginalized groups, poses a significant threat to democratic institutions and social cohesion. Moreover, this reactionary mindset can hinder societies from adapting to the challenges of the 21st century, such as climate change and global economic disparities.
Conclusion
The culture wars, fueled by the rapid advancement of AI and other technologies, have led to a resurgence of interest in fascist ideologies as a means of coping with the disorientation and alienation that accompanies such rapid change. It is essential that societies recognize the dangers posed by these reactionary movements...
This is such an interesting topic. I'm going to publish one soon proposing the risk isn't GPT or AGI per se but how we react to it. The biggest risk right now is that humans are projecting human emotions, intent, and interpretation on GPT already. We are anthromoporphizing and overattributing humanity onto an innanimate object. My theory is that it will achieve AGI, not when it can do what a human can (because that's hard) but when humans believe it. (which many already do)
Because to truely become sentient like humans you have a lot of other stuff to sort through in the brain.
https://polymathicbeing.substack.com/p/whats-in-a-brain