
Why Memory Defines AI Hardware Supremacy
The race to AI dominance is not just between companies anymore...



The 2020s: Models are getting cheaper and hardware is getting better, and many new datacenters are planned. So a bit of context:
Who to follow in Semiconductor Industry Coverage
With the rising demand for compute led by Nvidia and TMSC’s prominence especially over the last three years, with a huge increase in AI Infrastructure spending there’s never been a more exciting time to discover and understand the Semiconductor industry better.
When Semianalysis left Substack in late 2024 by Dylan Patel - it created a void in Semiconductor industry analysis on this platform not even Fabricated Knowledge could fill, however I’m excited to be reading new voices in one of the most lucrative Newsletter niches in Technology about semiconductors with independent voices like Ray Wang, Jukanlosreve, SEMIVISION (Jett Chen), AYZ, Claus Aasholm, Austin Lyons and the diamond in the rough that is Vikram Sekar, not so unknown any longer by the way as he’s been trending on the rising leaderboard for the past few months.
Also we should mention: Babbage, Subbu, SEMI INSIDER (Robert Quinn), Bharath Suresh, Judy Lin 林昭儀, Jon Y (who has also left following Dylan), Anastasiia Nosova, and too many others.
The Semiconductor category is now thriving in late 2025 like never before on Substack and I cannot recommend this type of reading enough. We are on the cusp of a world where suddenly TSMC, ASML, ARM, Broadcom, and SK Hynix are BigTech in their own right and Nvidia AI chips are changing the world. We should note that Vik works at Qualcomm.
Understand semiconductors. Stay ahead of the curve.’

What to expect on Vik’s Newsletter?
Weekly Technical Deep-Dives:
Short posts: On a weekday, he writes a short post that takes less than 5 minutes to read and breaks down small concepts in the context of semiconductors and chip design.
Actionable advice for students and professionals in the chip industry
New worldwide technology trends: Fresh insights from leading technical conferences and world-class experts in the field of semiconductor technology. (his body of work has reached a crescendo of value-add 🗺️)
Video Introduction (1 min, 11 seconds)
These featured articles should give you a quick relevant idea if this topic is for you:
Featured Articles
Why is High Bandwidth Memory so Hard to Manufacture?
Why the Chip Industry Is Struggling to Attract the Next Generation
A Comprehensive Primer on Advanced Semiconductor Packaging
A Short Introduction to Automotive Lidar Technology (#2 on HN, 20K+ views)
Why Documentation is the Missing Link Between AI and Chip Design
How Foundries Calculate Die Yield
Vik’s Newsletter (about) is a treasure chest 👑 of Semiconductor understanding. 🎓
Editor’s Note: SK Hynix's (South Korean firm) HBM bit shipment share was 62% (global market share) in the second quarter of 2025, up from 55% in the like period a year ago, according to Counterpoint Research. U.S.-based Micron is in second place. (August, 2025)
Micron's HBM market share was approximately 5.1% in 2024 and is projected to reach between 20% and 24% by the end of 2025, matching its overall DRAM market share, as the company aggressively ramps up shipments of its HBM3E products to customers like Nvidia and AMD. Micron’s stock ( MU 0.00%↑ ) is up 92.7% this year so far basically doubling.
Let’s get to Vik’s piece:

Why Memory Defines AI Hardware Supremacy
The race to AI dominance is not just between companies anymore; entire countries are involved. Hardware dictates what is possible from AI, which is why we are witnessing massive capital expenditures in AI datacenter buildouts like never before. In the core of all the compute, massive energy consumption, and billions of dollars spent, lies a key component that establishes a winner-take-all dynamic: High Bandwidth Memory, or HBM.
This post is a general overview of why HBM is so important, what makes it so, why it is so difficult to procure, and how it determines AI capabilities of entire nations. We will discuss:
The role of memory in computing
Why HBM is important for AI hardware
Where exactly is memory required in AI
Why HBM is so difficult to manufacture
Bottlenecks in packaging and substrates
Global dynamics and supply chains
How China is competing on memory
Let’s dive in!
Memory in Computing
We hear a lot about AI benchmarks. Test scores, leaderboards, and the long road to artificial general intelligence are usually framed in terms of intelligence benchmarks run on software. This gets a lot of attention because it translates hardware capability into a number that we can relate to and compare. Traditionally, gaming Graphics Processing Units (GPUs) have been measured the same way.
What gets far less attention is the role of memory in AI, at least outside the highly technical circles of the semiconductor industry. What most people don’t realize is that the strength of modern AI systems depends heavily on how they store information temporarily, how quickly they can access it, and how much they can hold at once.
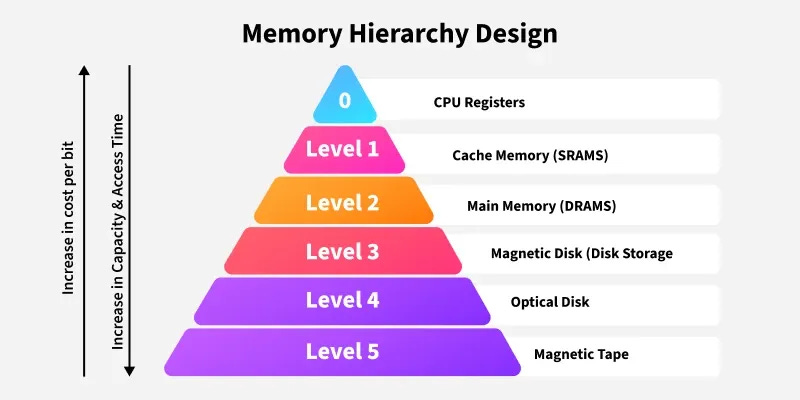
In computers, this is not a new concept. Random Access Memory (RAM) has always been the scratchpad for the processor. CPUs keep the most urgent data closest to the processor, and less urgent data farther away. For example, Static RAM (SRAM) cache memory present in the CPU itself is divided into levels such as L1, L2, and L3. These caches are expensive, but they are also the fastest because they reside on the CPU chip. The most critical information goes into L1, while less time-sensitive data is pushed further out to higher levels. Even less critical data is stored outside the CPU, on Dynamic Data Rate (DDR) RAM.
The Role of High Bandwidth Memory in AI
GPUs in AI accelerators work the same way, but the scale is different. Instead of relying on the familiar types of memory used in personal computers, GPUs in AI accelerators use a specialized and extremely expensive type of RAM called High Bandwidth Memory, or HBM.

Using DDR memory commonly found in PCs does not cut it. The data transfer rate from HBM is an order of magnitude faster compared to DDR and is designed for the demands of large-scale parallel processing. To serve AI at scale, modern GPUs need to drink from the memory firehose—HBM—failing which, they would be starved of the data they need to operate.
It’s not the math that consumes the most energy in AI chips, but the constant shuffling of data back and forth between the GPU and memory. HBM reduces the energy required to move each bit of data between memory and the GPU by being physically closer and providing a “high-bandwidth” connection – an order of magnitude faster than conventional memory chips like DDR used in personal computers. DDR would be untenable in terms of both power and latency costs.
There are only a handful of companies in the world that can manufacture HBM, which means it is not a commodity item like DDR memory. The complexity of making this memory drives up its cost. This scarcity makes it strategically unique in AI hardware. While GPUs are getting more powerful and able to handle large-scale inference, they are always constrained by the limits of what HBM can provide. HBM is a technical marvel and a clear reminder of how tightly coupled AI progress is to memory technology.
The performance and cost of memory has become one of the most important constraints on what AI systems can achieve today. Unlike software, which scales almost freely, memory scales with materials, factories, and billion-dollar supply chains. In this post, we will explore why AI supremacy will be decided by who can build, scale, and secure advanced memory systems.
How Memory Works in AI Systems
Why is memory important for large language models (LLMs)? The first reason is to store the model weights. Model weights are huge arrays of numbers, often billions or trillions, that the model needs in order to compute a response to your query.
The second reason is what is called the context window. This is how much input the model can remember at one time. For example, Google’s Gemini models now support a 1 million token context window. That means they can keep track of 700-800 hundred thousand words of text, which is almost the entire Harry Potter series at once, and still hold all the relationships between different parts of the text. Expanding this further to include the entire library of congress for instance, would require far more memory.
A token deserves a quick clarification. It can be a word, part of a word, punctuation, or some other unit of text. An LLM produces an output token for every input token it receives. To do this, it performs an enormous number of matrix multiplications on the arrays of numbers stored in memory. Through this process, it calculates a key quantity called “attention.” Attention, first introduced in Google’s 2017 paper Attention Is All You Need, is the core idea behind all modern transformer-based LLMs and is what gives LLMs their superpower.
This is also where High Bandwidth Memory (HBM) comes in. When an input is given to a model, the weights and tokens must be fed into the GPU so it can perform trillions of multiplications to produce an output token. For the model to respond quickly, this movement of data in and out of memory has to happen at very high speed. HBM is currently the only type of memory capable of meeting this need.
The lesson is simple: there is no point in making GPUs faster if they cannot be supplied with data in time. HBM helps overcome this bottleneck by keeping the flow of information steady and fast, which is why it has become so critical in both AI training and inference today.
The Incredible Engineering behind HBM

 |
|