
What is Reinforcement Learning with Human Feedback (RLHF)?
Deep Reinforcement Learning from Human Preferences is starting to really evolve.


Hey Everyone,
Hugging Face recently had an event that I found somewhat interesting on the topic of RLHF, you might want to check it out:
The authority for learning with human feedback is Deepmind back in 2017.
A promising approach to improve the robustness and exploration in Reinforcement Learning is collecting human feedback and that way incorporating prior knowledge of the target environment. The popularity of ChatGPT is such a case where a system can be improved by getting huge amounts of people to test it for free. Getting quality RLHF can be expensive, but Transformers once they reach a certain scale requires more emphasis on it.
Prompt Engineering as a part of the Generative A.I. is leading to new interactions of people and artificial intelligence. You might say that prompt engineering is the precursor to a brain-computer interface (BCI) in the sense that 2022 was the year of text-to-image interfaces with Stability.AI, Midjourney, DALL-E 2, Imagen and others.
Language models have shown impressive capabilities in the past few years by generating diverse and compelling text from human input prompts. We are just at the beginning of a Generative A.I. movement that could transform image, video, text, code and other kind of generated content.
GPT-3.5
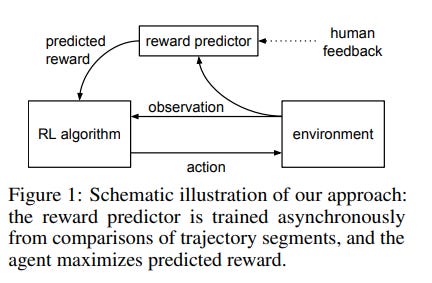
Reinforcement Learning from Human Feedback (RLHF); use methods from reinforcement learning to directly optimize a language model with human feedback. RLHF has enabled language models to begin to align a model trained on a general corpus of text data to that of complex human values.
RLHF's most recent success was its use in ChatGPT. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response. But it’s the interaction with human agents that make it get better at aligning with human preferences.
So metrics that are designed to better capture human preferences such as BLEU or ROUGE exist but RLHF needs to improve for A.I. to get better at adding value in the real world.
If you think about how ChatGPT rose to prominence as a demo in late 2022, it was trained using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. OpenAI rained an initial model using supervised fine-tuning: human AI trainers provided conversations in which they played both sides—the user and an AI assistant. They gave the trainers access to model-written suggestions to help them compose their responses.
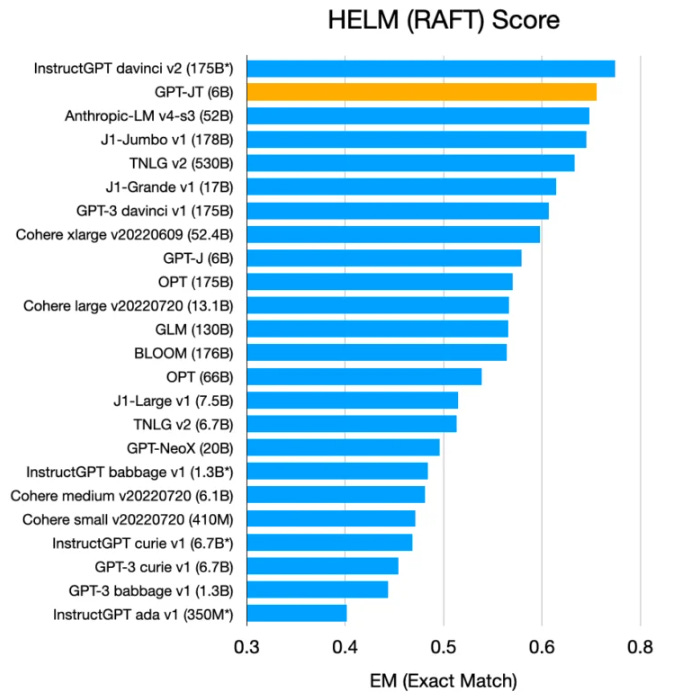
GPT-JT is also of notable interest here, before GPT-4 is announced in the coming months. Davinci-003 and GPT-3.5 are important developments in GPT-3’s evolution over the last couple of years.
