Hey Guys,
You’ve heard of text-to-image and maybe rumors of decent text-to-video Generative A.I. models but Nvidia’s place in the Metaverse with A.I. is somewhat misunderstood. Nvidia’s already has its own impressive text-to-image eDiff-I. TL;DR: eDiff-I is a new generation of generative AI content creation tool that offers unprecedented text-to-image synthesis with instant style transfer and intuitive painting with words capabilities.
In this article however I want to cover Nvidia’s work in text-to-3D called Magic3D.
On Friday November 18th, 2022 researchers from Nvidia announced Magic3D, an AI model that can generate 3D models from text descriptions. After entering a prompt such as, "A blue poison-dart frog sitting on a water lily," Magic3D generates a 3D mesh model, complete with colored texture, in about 40 minutes. With modifications, the resulting model can be used in video games or CGI art scenes

In its academic paper, Nvidia frames Magic3D as a response to DreamFusion, a text-to-3D model that Google researchers announced in September.
Think about it, 3D digital content has been in high demand for a variety of applications, including gaming, entertainment, architecture, and robotics simulation. Now with synthetic data being used more often to train A.I. and companies investing into a Metaverse for the 2030s, I’m really impressed by Nvidia’s approach to all of this. Nvidia’s Omniverse is perhaps the most likely to benefit from the intersection of Generative A.I. and the Metaverse, whatever it ends up being. Although I see Microsoft excelling at the Generative A.I. applications in Gaming and Enterprise products.
We’ll have to watch the space of Generative A.I. closely on this Newsletter, but even the way OpenAI is investing in it is showing some trends.
Generative A.I, has multiple applications that we do not fully realize in 2022. When you think of its applications to gaming, the Metaverse, architecture planning, urban planning and simulations of various kinds, the sky is the limit.
High-Resolution 3D Meshes
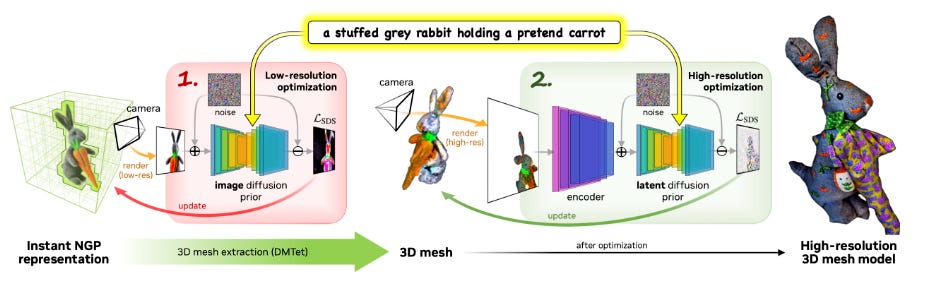
Magic3D can create high-quality 3D textured mesh models from input text prompts. It utilizes a coarse-to-fine strategy that leverages both low- and high resolution diffusion priors for learning the 3D representation of the target content. Magic3D synthesizes 3D content with 8× higher-resolution supervision than DreamFusion while also being 2× faster.
Faster than Google’s DreamFusion
Similar to how DreamFusion uses a text-to-image model to generate a 2D image that then gets optimized into volumetric NeRF (Neural radiance field) data, Magic3D uses a two-stage process that takes a coarse model generated in low resolution and optimizes it to higher resolution. According to the paper's authors, the resulting Magic3D method can generate 3D objects two times faster than DreamFusion.
Prompt-based Editing
Given a coarse model generated with a base text prompt, we can modify parts of the text in the prompt, and then fine-tune the NeRF and 3D mesh models to obtain an edited high-resolution 3D mesh.
In an era where digital artists can monetize with NFTs, you have to wonder what the digital creators of tomorrow will make? As Generative A.I. slowly begins to impact how games are developed, games could speed up in how fast they go to market. That will make entertainment opportunities of a much faster cycle.
How companies like Unity, Microsoft and Nvidia impact the future of gaming and transform game development with A.I. will be one of the more exciting things to watch in the 2020s.
According to the Nvidia researchers in the paper, 3D digital content is slowly finding its way into virtually every possible domain: retail, online conferencing, virtual social presence, education, etc. However, creating professional 3D content is not for anyone — it requires immense artistic and aesthetic training with 3D modeling expertise. Developing these skill sets takes a significant amount of time and effort. Augmenting 3D content creation with natural language could considerably help democratize 3D content creation for novices and turbocharge expert artists.
Retail
Online conferencing
Virtual social presence
Education
Social Commerce
Synthetic A.I. training
You can almost believe that Nvidia is setting itself up to be a major software provider if Metaverse apps become a thing.
Other Editing Capabilities
Given input images for a subject instance, we can fine-tune the diffusion models with DreamBooth and optimize the 3D models with the given prompts. The identity of the subject can be well-preserved in the 3D models.
Text-to-3D is in its infancy. The key enablers of text-to-image are large-scale datasets comprising billions of samples (images with text) scrapped from the Internet and massive amounts of compute. In contrast, 3D content generation has progressed at a much slower pace.
What will this then become when larger diverse large-scale 3D datasets are available and how will they interact with text-to-image and text-to-video media when a potential convergence takes place?
Method
The Nvidia researchers utilize a two-stage coarse-to-fine optimization framework for fast and high-quality text-to-3D content creation. In the first stage, they obtain a coarse model using a low-resolution diffusion prior and accelerate this with a hash grid and sparse acceleration structure. In the second stage, they use a textured mesh model initialized from the coarse neural representation, allowing optimization with an efficient differentiable renderer interacting with a high-resolution latent diffusion model.